More MapReduce
This thing's pretty important.
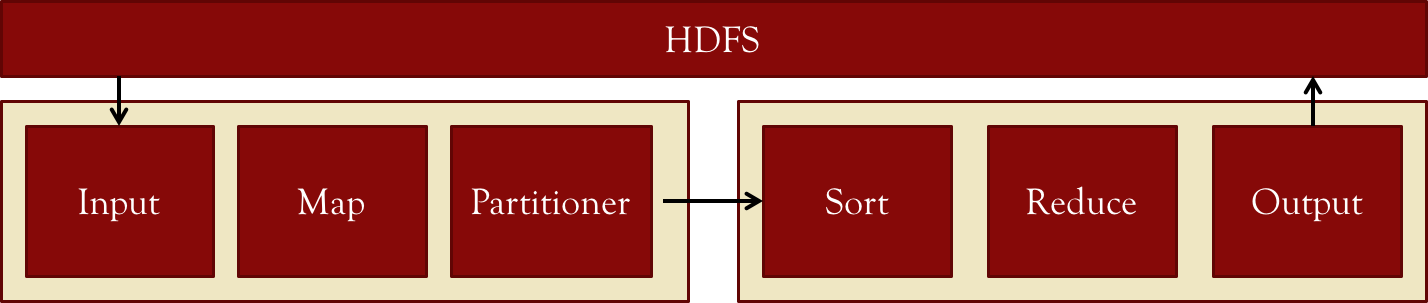
Input
This is key-value pairs.
Map
Operates on each input, parses it and outputs intermediate KV pairs.
Partitioner
Distributes intermediate KV pairs and nominates the target reducer for keys.
Normally a hash function, but can be overriden.
Shuffle/Sort
Shuffle redirects the Mapper output to the correct Reducer.
Sort sorts the input to each Reducer after the shuffle.
Reduce
Receives the sorted intermediate KV pairs, and aggregates their values by key.
Output
Writes the output to HDFS (one file per reducer, e.g. Part-r-0001).
Also, Combiners
A Combiner is a Map-side reducer. It is used to decrease the amount of data transferred between nodes in the network.
Instead of sending a bunch of <key,1>, use a Combiner to send <key,n>.
Full example (average tweets)
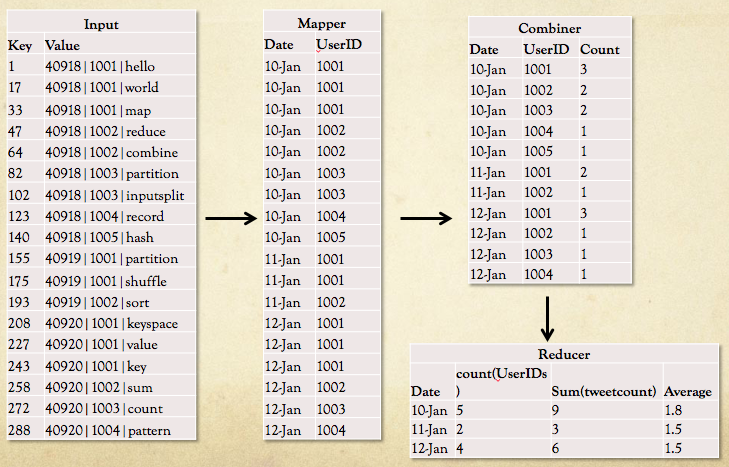
Remember the code still has to be written to e.g. use UserID in the mapper.