Introduction to Hadoop
Hadoop is composed of two parts:
- A processing part, which does MapReduce (read paper here); and
- A storage part, the HDFS (Hadoop Distributed File System).
- Distributes data across nodes and is natively redundant; and
- Is easily scalable by adding more machines.
MapReduce
This is what MapReduce looks like. For thorough information about how it works in practice (or how it was conceived to work) please read the whitepaper, linked above.
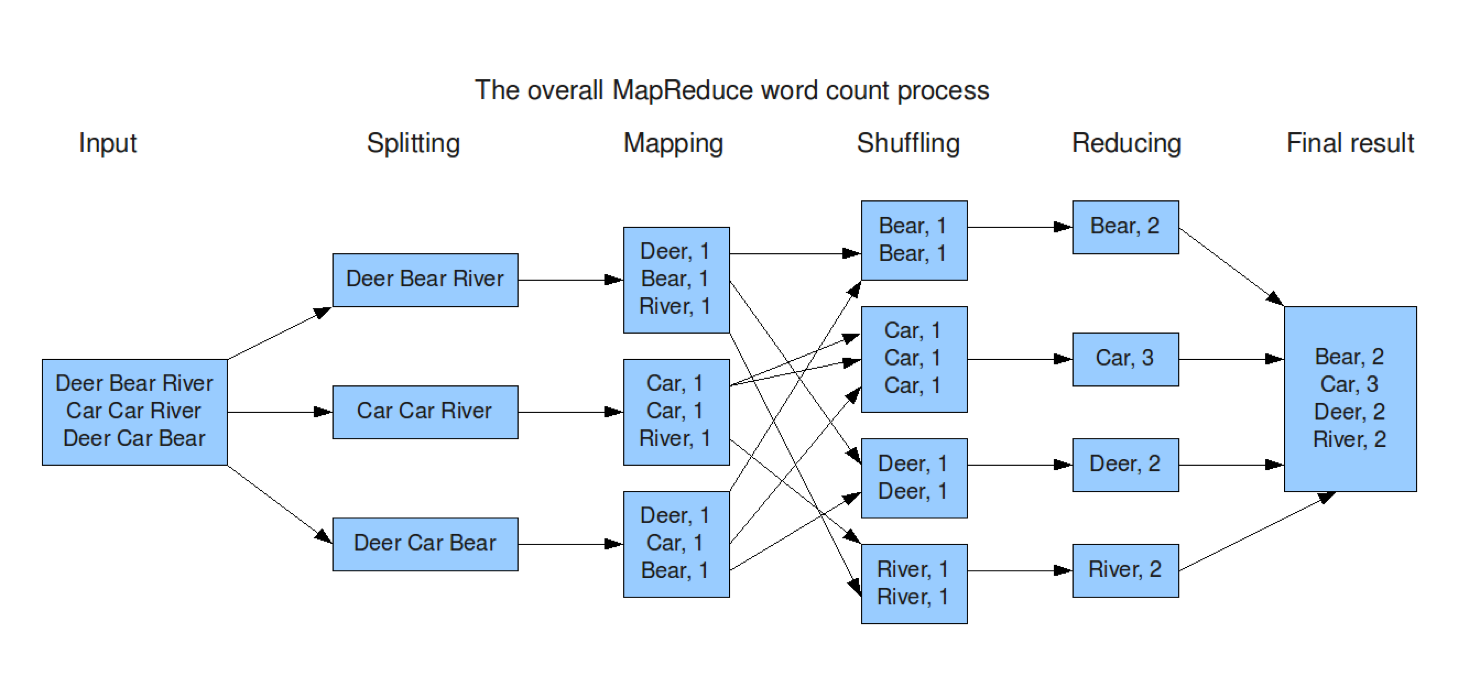
- The master thread gets the input;
- It spawns a thread for each section that it can split into;
- Each one of those threads produces a mapping (in this case, counting the words in the section);
- Data is shuffled so each thread only holds one group of data that can then be reduced;
- Data is reduced in the thread (here, added together is the reduction); and
- All threads communicate with the master thread and give it their counts. The master threads reduces further to a single list, in this case.
HDFS
HDFS is a distributed file system. Files are split into chunks (of default 64Mb) and copied around nodes. By default, the number of times each file is duplicated is 3. This is the Replication Factor.
NameNode
Prior to version 2 of Hadoop, there was only 1 NameNode, which essentially said where the nodes are and how they can be found.
After version 2, multiple NameNodes can exist for resilience, in case one goes down.
Sizing a Hadoop cluster
By Data
- Imagine your system has
80Tbof data. With the default Replication Factor of 3, you would need240Tbof storage across all your nodes. - Recommended
2Tbdisk per CPU core. - Recommended
4GbRAM per CPU core.
So for servers with 12 cores, you would need 10 of them.
Disk: 2Tb per Core, 24 cores = 240Tb total data.
Plus 2 servers for a NameNode and a secondary NameNode, but these need not be as powerful.
By Performance
Sample out the workload and code, and then run on e.g. an EC2 instance. Hadoop scales linearly, so use the test results to calculate how much you need.
Hadoop Use Cases
- Web log processing;
- Text search;
- Social network analysis;
- Batch pre-processing;
- Last.fm - Analytics;
For more, http://wiki.apache.org/hadoop/PoweredBy.