Cassandra Topology and Structure
Cassandra is distributed, so uses multiple nodes. It can also be rack-aware for when it is occupying entire racks of server space.
Keys can be replicated across nodes.
It is essentially a DHT (Distributed Hash Table), like BitTorrent.
Let's imagine we have a Cassandra system structured as follows:
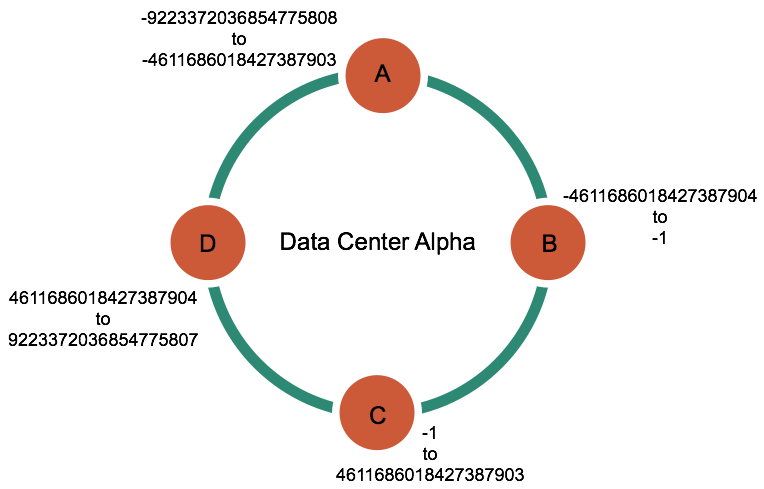
Cassandra implementations are always structured and seen as rings.
There are four nodes, and data is split between them. The way data is split depends on the partitioner:
- Murmur3 Partitioner:
- Uniformly distributes data across the cluster based on MurmurHash values.
- Random Partitioner:
- Uniformly distributes data across the cluster based on MD5 hash values.
- ByteOrdered Partitioner:
- Keeps an ordered distribution of data lexically by key bytes.
The most common (and default) one is Murmur3.
How does the partitioner work?
Each row must have a Partition Key specified. For example, this could be the ID field of a row.
The Murmur3 Partitioner then calculates a MurmurHash token of the ID for each row, and depending on the ID, the row is placed in one node or another.
So if the MurmurHash token of the ID was 4611686018427387905 (notice it is 1 over the lower limit of D), then the data would live in node D.
The MurmurHash limits are between -2^63 and 2^63-1, so that range will be split between the nodes, and each node will be responsible for their section of the range.
For more information about this read the official documentation.
Prior to Cassandra 1.2, you had to calculate and assign a single token to each node in a cluster. Each token determined the node's position in the ring and its portion of data according to its hash value. In Cassandra 1.2 and later, each node is allowed many tokens. The new paradigm is called virtual nodes (vnodes).